
当数据出现波动时,数据分析师不免要对导致数据波动的背后原因进行筛查,进而找到解决路径。然而,数据异常的原因该怎么找,才是准确且合理的呢?本文作者便总结了一套从0到1搭建数据异常监控体系的有效策略,也许会对你有所帮助。
前言
日常观察业务数据时,如果数据出现波动,我们心里总会犯嘀咕:这个波动到底是不是在正常范围内?如果数据与业务预期相差了好几倍,那我们又头疼了,原因那么多,到底哪个才是导致数据波动的原因?
别慌,这篇文章中,教你从0-1搭建数据异常监控体系。
数据分析师的面试总是绕不开一类经典的案例题:
如果日活下降了,你会怎么定位问题?
如果销售额上升了,你会如何寻找原因?
总结一下这类问题的形式:
如果XX指标发生了波动(上升或下降),需要你去定位原因,你的分析思路是什么?
这里大部分人的回答是,我会看看数据具体的波动时间是什么时候?然后看看当天我们有没有做什么活动或者产品改版?
业务经验丰富一点的还会说,我会把用户分成新老用户,看看具体是哪个人群结构发生了波动?我还会……
这样回答有问题吗?没有,但是回答得好不好呢?可能你自己心里也犯嘀咕,因为我们这种东一榔头西一棒槌的答法,有没有漏掉什么我们自己心里也没有底。
实际上,对于这种数据波动的问题,考察的是你系统性思考的能力,也就是能否站在全局角度,通过严谨的逻辑与业务结合来思考问题。
所以,今天和大家分享如何从0-1搭建数据异常监控体系。
一、数据异常检测
数据异常。所谓异常,可以理解为不符合预期的数据。这里的预期可以分为两个部分:业务预期和合群预期。
业务预期:业务上不符合预期;
合群预期:波动或空间上不符合预期。
业务预期比较好理解,有经验的业务人员在做一次新的运营活动时,心里往往会有个预期的数据值。当实际值在心里预期之外,可能就需要拉着分析师找原因。
合群预期是一种定量的判断,有两个条件:
异常数据跟样本中大多数数据不太一样;
异常数据在整体数据样本中占比比较小。
所以重点在合群预期的判断上,转换成业务语言就是:什么样的波动才算是异常呢?日活从20w掉到15w算不算异常?
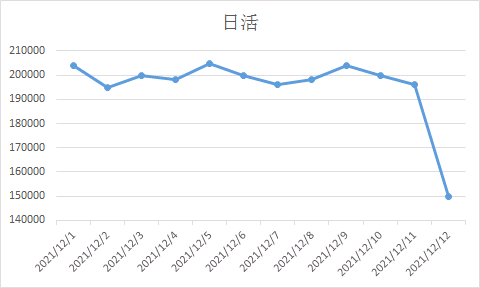
如果我们每天的日活如下图所示,(思茅seo网站快速排名),在20w上下波动,(抖音直播怎么放音乐),突然掉到15w,算不算异常?
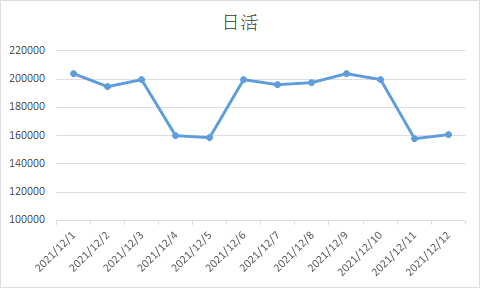
如果我们的日活如下图所示,具有明显的周期性波动(工作日在20w左右,节假日在15w左右),那12月12日的日活为15w,算不算异常?
通过上面的例子,(网站开发的流程或者步骤是什么?),我们知道,所谓异常,要结合具体的业务场景来看,对于合群预期,有没有科学的方法来检测数据波动导致的异常与否?
答案是有的,对于波动异常检测的方法主要有:z-score检测(3sigma准则)、分位数分析、孤立森林、聚类、lof局部异常因子检测、one-class svm(适用高维空间)等。
下面简单介绍下常用的3sigma准则是如何判别异常的。
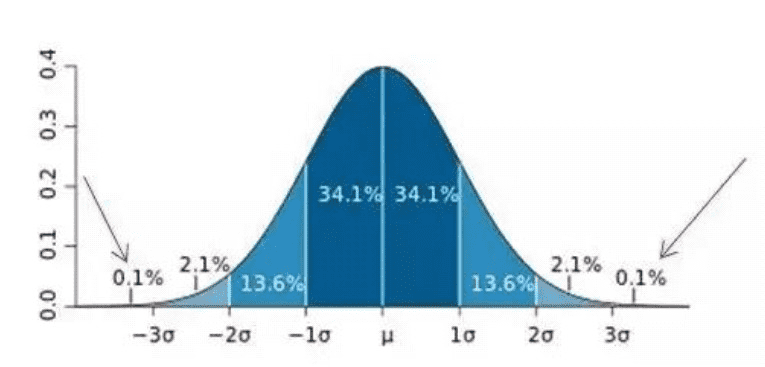
统计学教材中,关于3sigma的定义为:正态分布下,数据落在μ±3σ区间内的概率为99.7%。
所以对于任意一组数据,只要我们知道了μ和σ,那我们就可以设定正常值的上下限(μ-3σ,μ+3σ),只要在这个范围之外的值,我们就认为是异常值。
关于如何判定异常值还有很多已经成熟的方法,这里不做展开。
二、数据异常定位
从上面我们已经知道了在一组数据中,如何判断新加入的一个数据是否是异常,那如果出现了异常,我们如何定位?
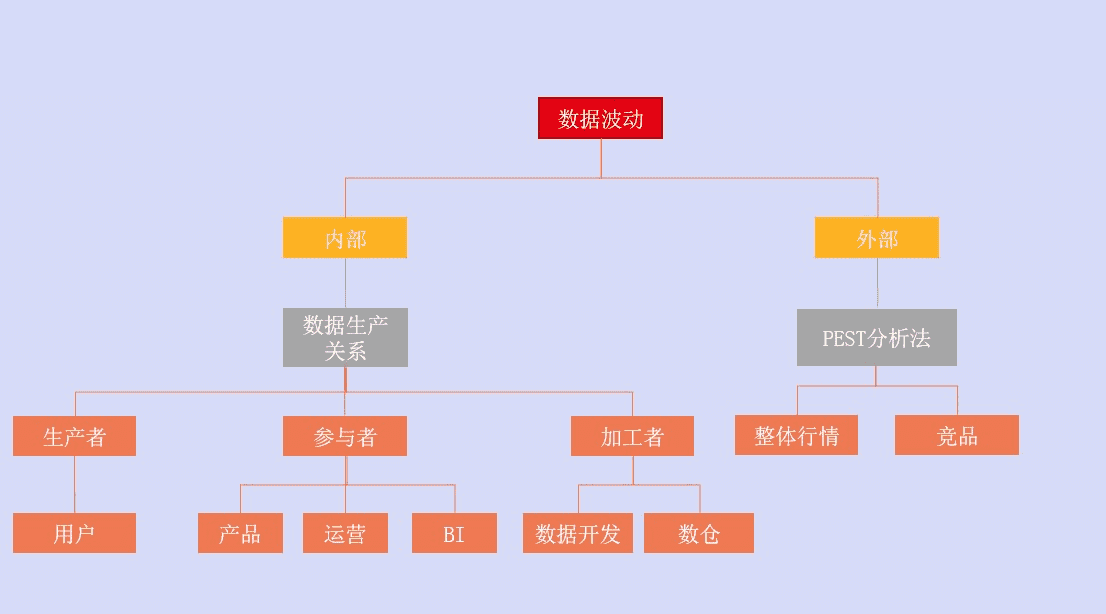
我们把异常数据的定位分成两块去拆解:内部因素和外部因素。
1. 外部因素定位
外部因素我们一般采用PEST分析法(宏观经济环境分析),即通过四个方面去分析:政治、经济、社会、技术。
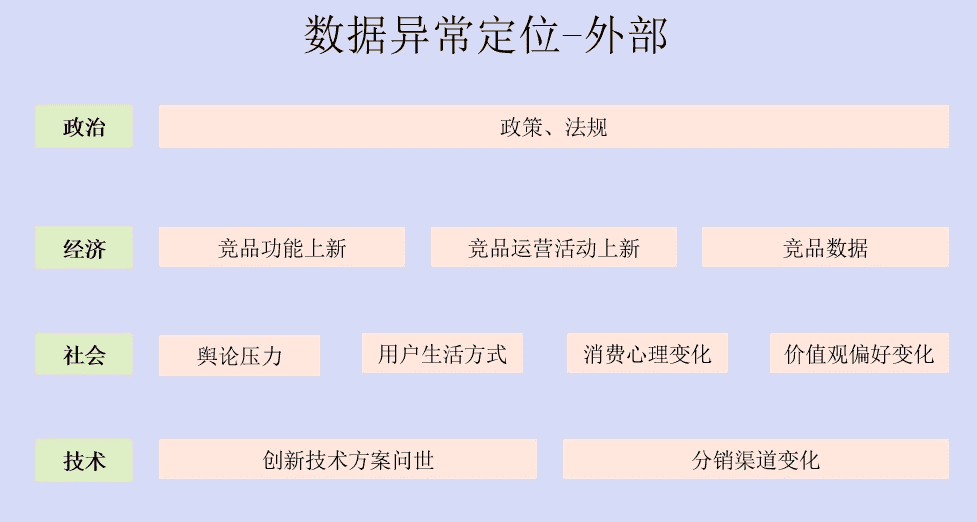
政治层面主要是新颁布的一些政策、法规对数据产生影响。如最近的滴滴上市被叫停,各应用市场禁止上架APP,那么滴滴的新用户数在政策颁布之后一定会下降。
经济,这里我为了理解方便,列了三个维度:竞品功能上新、竞品运营活动上新、竞品数据。这里主要是考虑到竞品的变动导致了我们数据的波动。
还是以打车软件为例,A打车软件最近对全体用户搞了一个新的运营活动,花1元钱可以购买五张6.5折的打车券,且在工作日无时间限制。
假设这个活动的参与用户很多,且A软件和B软件的重合用户较多,(快手运营定位),那么A软件此次的运营活动就会影响到B软件的用户数据,毕竟人是“趋利”的。
假设我们既没发现竞品有功能更新、又没有新的运营活动呢?那么我们可以看下我们出现波动的指标,(淘宝直通车出价技巧),在竞品中有没有出现变化。
举个例子,如果我们发现我们的用户次日留存在某个时间段出现下降。如果主要竞品也出现了同样特征的波动,在其他条件都一样的情况下,我们就可以判定是市场情绪出现了波动,(阳新网站快速排名),大家都“下降”了。
社会因素主要是舆论压力,用户生活方式、消费心理变化、价值观变化的改变对我们的数据造成的影响。
技术层面指的是一些创新技术的问世等带来的影响。这两种因素带来的数据影响一般不会是突然的,用户生活方式的改变、新技术的应用都需要大量的时间积累才会造就。
所以这两个因素如果存在的话,在数据上的表现会是缓慢下降的趋势,而不是突升或突降。
2. 内部因素定位
实际业务过程中,数据波动由内部因素导致的可能性更高。
数据出现波动,那么和数据相关的系统都需要排查是否出现问题。在内部因素的定位中,我们按照数据的生产关系将各参与系统分成:生产者、参与者、加工者三个部分。
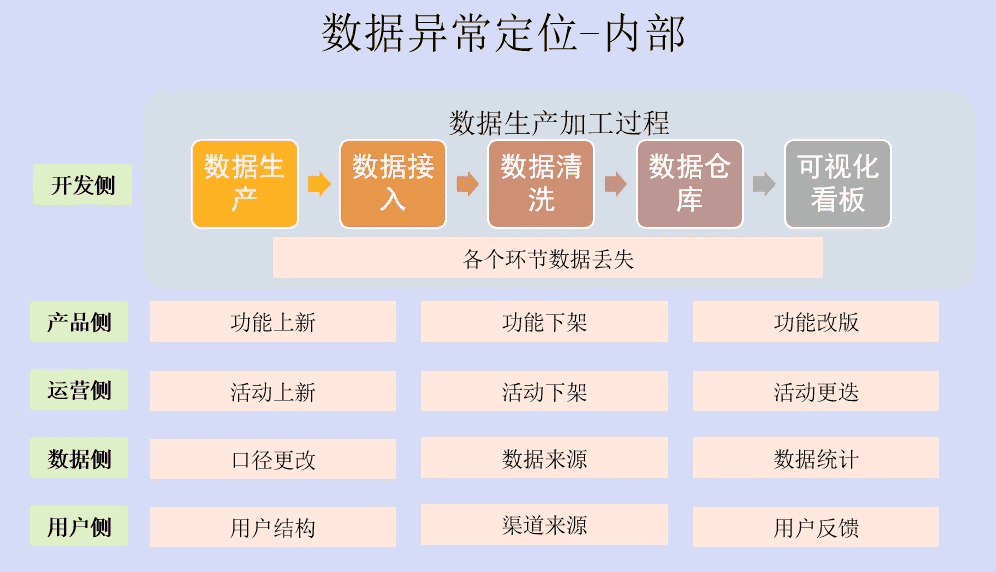
其中生产者是用户。所有用户的行为都由用户产生。那么用户侧可能出现什么问题?比较常见的是用户结构出现变化、渠道来源出现调整,用户反馈出现变化。
用户结构指的是我们在对业务过程搭的指标体系中,按照用户属性将用户分成:新用户、次新用户、老用户、流失用户(当然,这个不同业务形态区分的维度也不同)。
如果我们的新用户突然变多,本身新用户的活跃度就比不上老用户,再加上新用户占到我们日活的50%,那么这样的情况反映到数据上就是日活的次日留存降低,整体用户的活跃度也降低。
当然我们还可以根据用户地域分布、性别、机型、登录时段等维度来定位用户。用户维度分得越细,我们的定位就会“快”而“准”。
数据参与者是产品侧、运营侧、BI侧。
产品侧比较好理解。我们产品功能的上新、老功能的下架,已有功能的改版,都会导致数据的波动。
运营侧也是同理。双11我们新运营活动的上线,之前的运营活动下架,已有活动改版之后新的玩法,都会对数据造成波动。
所有的数据可视化基本上都是由BI开发的一个个报表堆砌的,所以BI也是数据的重要参与者。由BI侧导致的数据波动大多数出现在口径不一致的问题上。
这里可能有很多产品和运营的小伙伴深有同感,自己公司的BI经常会在不同时间点给出统一口径下的两份不同数据。
这里我为广大的BI同学们正名一下,作为BI,数据的准确性是我们的红线,给出准确的数据是我们的义务。但是往往随着公司业务规模的扩大,之前的底层数据架构开始不堪重负。再加上人员的流动,很多历史遗留问题开始凸显。这时,大多数的公司还处在追求业务扩张的阶段,不会花时间和资源来处理数据底层架构的问题,(公司网站维护怎么弄?),毕竟花时间又看不出明确产出。
这个问题的破局只有自上而下,具体在这里不细说。
最后一个生产关系是数据的加工者,即开发侧的数据开发、数仓。这是最容易忽视却是出问题频率较高的部分。
这里要简单说下我们的数据生产加工过程。用户生产的行为、属性等数据并不是直接生成的可视化报表,(抖音上热门不花钱的技巧),需要经过ETL清洗、数据入库、再到数据处理,最后成为可视化看板。
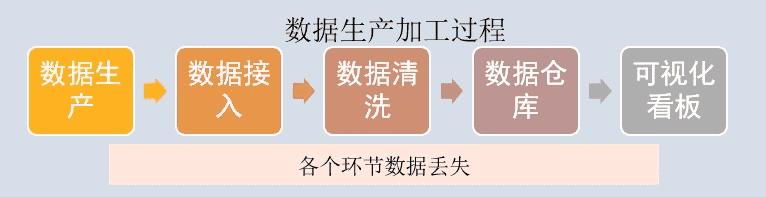
而在上述的每个环节中,都可能会造成数据丢失的问题。常出现的问题有对接的服务器漏采集数据,传输数据的服务器之间未添加白名单导致数据丢失等。
很多时候查到这里确认是这个问题后,我们会恍然大悟。
三、数据异常归因
经过前面两步:数据异常检测、数据异常定位,我们基本上定位到了数据波动的因素,那究竟是不是这个因素导致了我们的波动?
这里举个例子方便大家理解我们为什么还要做归因这个步骤。比如五年级的小明在之前几次月考中数学都在95分左右,但期中考试数学只考了80分,小明妈妈非常不满意,认为是小明最近一直在玩手游导致的成绩下降。小明很委屈,他觉得这次是题目太难了。
妈妈为了证明是手游这个因素影响了小明的成绩,从期中考试结束后到期末考试期间,(京东开店流程),严格禁止小明玩手机。结果小明期末考试考了95,达到平时的成绩,小明妈妈就更坚定了是手游影响了小明的学习。
这里举的例子对应到业务中,也就是说在数据异常定位之后,我们还要证明确实是这个因素的变动导致了结果数据的变动。
在这个环节我们都是采用AB实验的思想,比如我们定位到了是新增用户变多导致了我们整体次日留存的下降。那我们就可以保证其他因素不动,只是剔除新用户,再取一下次日留存的数据,看看数据是否依然波动。
四、总结
还记得我们一开始的问题吗?
如果XX指标发生了波动(上升或下降),需要你去定位原因,你的分析思路是什么?
通过我们前面的讲解,我们会这样回答:
通过数据异常检测确认业务所说的波动是否属于异常波动;
根据外部因素和内部因素分别进行排查;
用AB实验的思想进行数据异常归因。
其中外部采用PEST分析法,内部因素按照数据生产关系分为生产者、参与者、加工者,在对每个层级分别排查定位问题。
微信公众号:董点数据。分享产品、运营、数据思维。
