
摘要: 色情业是个大行业。互联网上没有多少网站的流量能和最大的色情网站相匹敌。要搞定这巨大的流量很难。更困难的是,在色情网站上提供的很多内容都是低延迟的实时流媒体而不是简单的静态视频。但是对于所有碰到过的挑战 …
色情业是个大行业。互联网上没有多少网站的流量能和最大的色情网站相匹敌。要搞定这巨大的流量很难。更困难的是,在色情网站上提供的很多内容都是低延迟的实时流媒体而不是简单的静态视频。但是对于所有碰到过的挑战,我很少看到有搞定过它们的开发人员写的东西。所以我决定把自己在这方面的经验写出来。
问题是什么?
几年前,我正在为当时全世界访问量排名26的网站工作 — 这里不是说的色情网站排名,而是全世界排名。
当时,该网站通过RTMP(Real Time Messaging protocol)协议响应对色情流媒体的请求。更具体地说,它使用了Adobe的FMS(Flash Media Server)技术为用户提供实时流媒体。基本过程是这样的:
用户请求访问某个实时流媒体
服务器通过一个RTMP session响应,播放请求的视频片段
因为某些原因,FMS对我们并不是一个好的选择,首先是它的成本,包括了购买以下两者:
为每一台运行FMS的服务器购买Windows的版权
大约4000美元一个的FMS特定版权,由于我们的规模,我们必须购买的版权量数以百计,而且每天都在增加。
所有这些费用开始不断累积。撇开成本不提,FMS也是一个比较挫的产品,特别是在它的功能方面(我过一会再详细说这个问题)。所以我决定抛弃FMS,自己从头开始写一个自己的RTMP解析器。
最后,我终于把我们的服务效率提升了大约20倍。
开始
这里涉及到两个核心问题:首先,RTMP和其他的Adobe协议及格式都不是开放的,(淘宝运营可以自学吗),这就很难使用它们。要是对文件格式都一无所知,你如何能对它进行反向工程或者解析它呢?幸运的是,有一些反向工程的尝试已经在公开领域出现了(并不是Adobe出品的,(抖音上热门审核不通过钱会退回来吗),而是osflash.org,它破解了一些协议),(哪里有网站开发制作),我们的工作就是基于这些成果。
注:Adobe后来发布了所谓的“规格说明书”,比起在非Adobe提供的反向工程wiki和文档中披露的内容,这个说明书里也没有啥新东西。他们给的规格说明书的质量之低劣达到了荒谬的境地,近乎不可能通过该说明书来使用它们的库。而且,协议本身看起来常常也是有意做成具有误导性的。例如:
他们使用29字节的整形数。
他们在协议头上所有地方都采用低地址存放最高有效字节(big endian)的格式,除了在某一个字段(而且未标明)上采用低地址存放最低有效字节(little endian)的格式。
他们在传输9K的视频时,不惜耗费计算能力去压缩数据减少空间,这基本上是没意义的,因为他们这么折腾一次也就是减少几位或几个字节,对这样的一个文件大小可以忽略不计了。
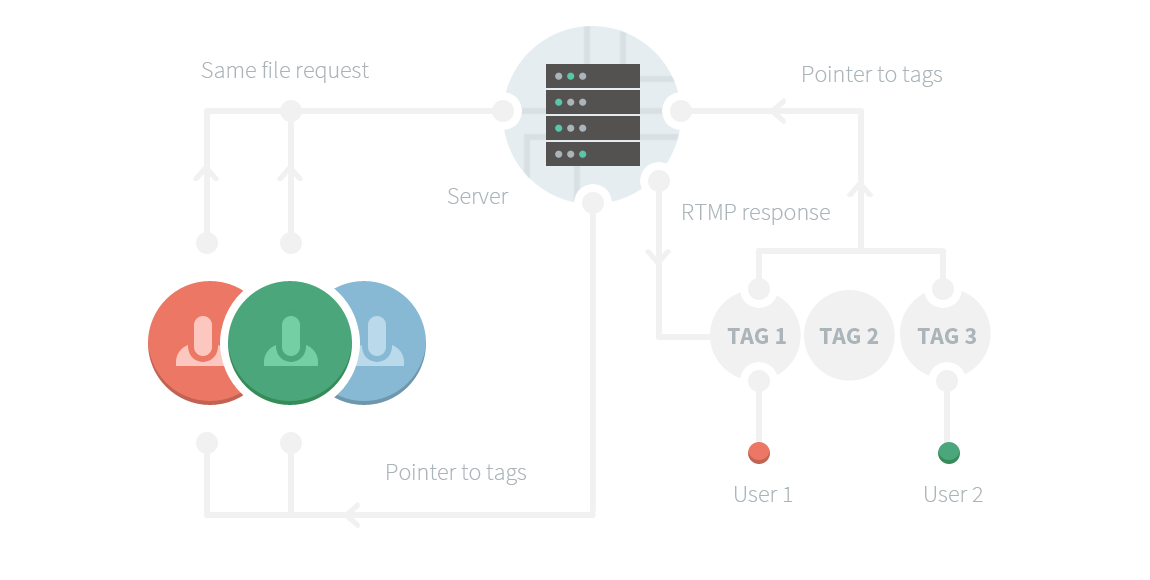
还有,RTMP是高度以session为导向的,这使得它基本上不可能对流进行组播。理想状态下,如果多个用户要求观看同一个实时视频流,我们可以直接向他们传回指向单个session的指针,在该session里传输这个视频流(这就是组播的概念)。但是用RTMP的话,我们必须为每一个要求访问特定流的用户创建全新的一个实例。这是完全的浪费。
我的解决办法
想到了这些,(抖音直播需要什么设备),我决定把典型的响应流重新打包和解析为FLV“标签”(这里的“标签”指某个视频、音频或者元数据)。这些FLV标签可以在RTMP下顺利地传输。
这样一个方法的好处是:
我们只需要给流重新打包一次(重新打包是一个噩梦,因为缺少规格说明,(公司网站维护),还有前面说到的恶心协议)。
通过套用一个FLV头,我们可以在客户端之间顺畅地重用任何流,而用内部的FLV标签指针(配以某种声明其在流内部确切位置的位移值)就可以访问到真正的内容。
我一开始用我当时最熟悉的C语言进行开发。一段时间后,这个选择变得麻烦了,所以我开始学习Python并移植我的C代码。开发过程加快了,但在做了一些演示版本后,我很快遇到了资源枯竭的问题。Python的socket处理并不适合处理这些类型的情况,具体说,我们发现在自己的Python代码里,每个action都进行了多次系统调用和context切换,这增加了巨大的系统开销。
改进性能:混合使用Python和C
在对代码进行梳理之后,我选择将性能最关键的函数移植到内部完全用C语言编写的一个Python模块中。这基本是底层的东西,具体地说,它利用了内核的epoll机制提供了一个O(log n)的算法复杂度。
在异步socket编程方面,有一些机制可以提供有关特定socket是否可读/可写/出错之类的信息。过去,开发人员们可以用select()系统调用获取这些信息,但很难大规模使用。Poll()是更好的选择,但它仍然不够好,(抖音上热门多少钱效果明显),因为你每次调用的时候都要传递一大堆socket描述符。
Epoll的神奇之处在于你只需要登记一个socket,系统会记住这个特定的socket并处理所有内部的杂乱的细节。这样在每次调用的时候就没有传递参数的开销了。而且它适用的规模也大有可观,它只返回你关心的那些socket,相比用其他技术时必须从10万个socket描述符列表里挨个检查是否有带字节掩码的事件,其优越性真是非同小可啊。
不过,为了性能的提高,我们也付出了代价:这个方法采用了完全和以前不同的设计模式。该网站以前的方法是(如果我没记错的话)单个原始进程,在接收和发送时会阻塞。我开发的是一套事件驱动方案,所以为了适应这个新模型,(闲鱼流量限制怎么破),我必须重构其他的代码。
具体地说,在新方法中,我们有一个主循环,它按如下方式处理接收和发送:
接收到的数据(作为消息)被传递到RTMP层
RTMP包被解析,从中提取出FLV标签
FLV数据被传输到缓存和组播层,在该层对流进行组织并填充到底层传输缓存中
发送程序为每个客户端保存一个结构,包含了最后一次发送的索引,并尽可能多地向客户端传送数据
这是一个滚动的数据窗口,并包含了某些试探性算法,当客户端速度太慢无法接收时会丢弃一些帧。总体来说运行的很好。
系统层级,架构和硬件问题
但是我们又遇到另外一个问题:内核的context切换成为了一个负担。结果,我们选择每100毫秒发送一次而不是实时发送。这样可以把小的数据包汇总起来,也避免了context切换的爆炸式出现。
也许更大的一个问题在于服务器架构方面:我们需要一个具备负载均衡和容错能力的服务器集群,毕竟因为服务器功能异常而失去用户不是件好玩的事情。一开始,我们采用了专职总管服务器的方法,它指定一个”总管“负责通过预测需求来产生和消除播放流。这个方法华丽丽地失败了。实际上,我们尝试过的每个方法都相当明显地失败了。最后,我们采用了一个相对暴力的方法,在集群的各个节点之间随机地共享播放的流,使流量基本平衡了。
这个方法是有效的,但是也有一些不足:虽然一般情况下它处理的很好,我们也碰到了当所有网站用户(或者相当大比例的用户)观看单个广播流的时候,性能会变得非常糟糕。好消息是,除了一次市场宣传活动(marketing campaign)之外,这种情况再也没出现过。我们部署了另外一套单独的集群来处理这种情况,但真实的情况是我们先分析了一番,觉得为了一次市场活动而牺牲付费用户的体验是说不过去的,实际上,这个案例也不是一个真实的事件(虽然说能处理所有想象得到的情况也是很好的)。
结论
这里有最后结果的一些统计数字:每天在集群里的流量在峰值时是大约10万用户(60%负载),平均是5万。我管理了2个集群(匈牙利和美国),每个里有大约40台服务器共同承担这个负载。这些集群的总带宽大约是50 Gbps,在负载达到峰值时大约使用了10 Gbps。最后,我努力做到了让每台服务器轻松地能提供10 Gbps带宽,也就等于一台服务器可以承受30万用户同时观看视频流。
已有的FMS集群包含了超过200台服务器,我只需要15台就可以取代他们,而且其中只有10台在真正提供服务。这就等于200除以10,等于20倍的性能提高。大概我在这个项目里最大的收获就是我不应让自己受阻于学习新技能的困难。具体说来,Python、转码、面向对象编程,这些都是我在做这个项目之前缺少专业经验的概念。
这个信念,以及实现你自己的方案的信心,会给你带来很大的回报。
【1】后来,(抖音直播需要什么设备),当我们把新代码投入生产,我们又遇到了硬件问题,(淘宝直通车抢位助手),因为我们使用老的sr2500 Intel架构服务器,由于它们的PCI总线带宽太低,不能支持10 Gbit的以太网卡。没辙,我们只好把它们用在1-4×1 Gbit的以太网池中(把多个网卡的性能汇总为一个虚拟网卡)。最终,(抖音上热门的钱怎么退),我们获得了一些更新的sr2600 i7 Intel架构服务器,它们通过光纤达到了无性能损耗的10 Gbps带宽。所有上述汇总的结果都是基于这样的硬件条件来计算的。
